こんにちは。開発ブログ運営担当のktです。
開発をしていると文字をチェックする処理であったり、置換する処理で正規表現を利用することが多々あると思います。
私はエンジニアになりたての時に、ソースコードから余分なスペースを取り除くのに正規表現を利用する方法を教えてもらい、なんて便利なんだと思った記憶があります。
そんな便利な正規表現ですが、今回はその一つの「否定後読み」について紹介しようと思います。
【前置き】
よくある正規表現の利用シーンとして、あるパターンに一致する部分を見つけて、その一致した部分を他の文言に置き換えることがあります。例えば「090-1234-5678」のような電話番号のデータがあるとして、頭3桁と最後1桁だけは残してそれ以外の数字は隠すため「#」に置換したいとします。
その場合置換前のパターンは「\d{4}-\d{3}」で、置換後の文字列は「####-###」になります。
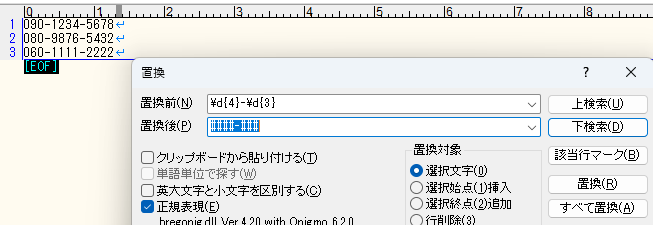
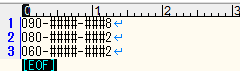
簡単に説明すると「\d{4}-\d{3}」で中間の4桁とそれに続く数字3桁とマッチします。
それを「####-###」で置換します。
このようにあるパターンに一致した部分を置き換える処理はすんなりと理解できると思いますが、今回紹介する「否定後読み」は、ある特定の文字列の前に特定のパターンが存在しないことを条件として、その後の文字に一致させることができるという言葉にすると一見理解しにくいパターンになります。
【本題】
例えば下記のような整形されたSQL文がいくつかある時に、SQLの1文を1行にしたいとします。

単純に改行コードの「\r\n」をブランクと置換したとしましょう。
![]()
全てが1行になってしまいました。
SQLの1文の最後の改行コードは置換したくありません。
そこで「否定後読み」の出番です。
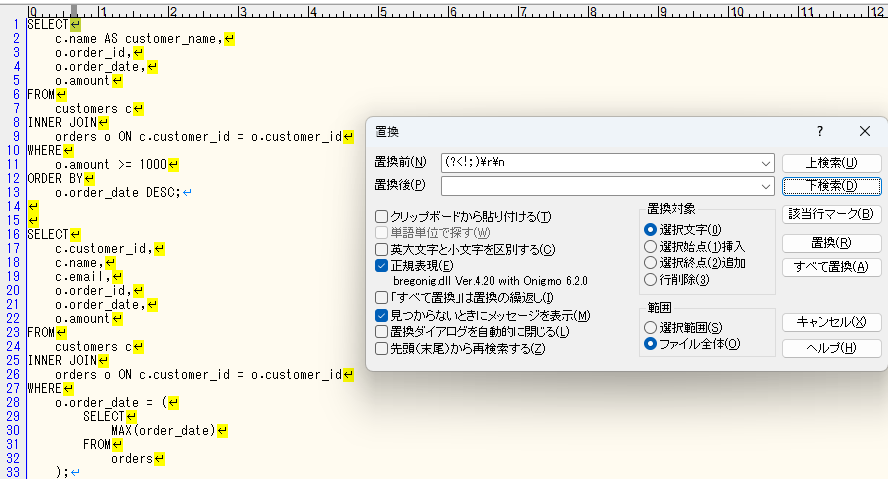
パターンは「(?<!;)\r\n」です。
「(?<!;)」でセミコロンが前にないという条件になり「\r\n」で改行コードと一致します。
これをブランクと置換すると、やりたかったSQLの1文を1行にすることができました。

今回紹介したのは「否定後読み」ですが、否定もあれば反対の肯定もあり、後読みもあれば先読みもあります。
気になる方はそれらも調べてみてください。
利用する機会としてはあまり無いかもしれませんが、知っていると役立つ場面もあるかもしれませんね。